Introduction:
In the rapidly evolving field of machine learning, adapting large pre-trained models to new tasks without significant computational overhead is a critical challenge. Parameter-efficient Fine-tuning (PEFT) emerges as a solution, allowing for the efficient adaptation of these models while maintaining performance. This article delves into the concept of Parameter-efficient Fine-tuning, explaining its significance, methodologies, and advantages in a clear and straightforward manner.
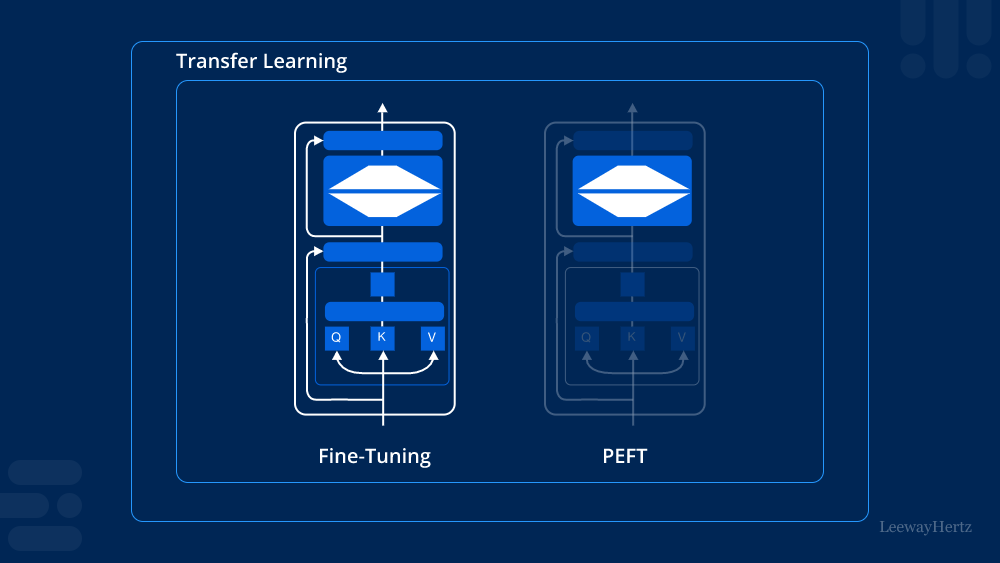
What is Parameter-efficient Fine-tuning (PEFT)?
Parameter-efficient Fine-tuning (PEFT) is a technique used to adapt pre-trained models to specific tasks by fine-tuning only a small subset of their parameters. Traditional fine-tuning methods involve adjusting all parameters of a pre-trained model, which can be computationally expensive and memory-intensive, especially when dealing with large-scale models. PEFT, however, focuses on fine-tuning a minimal number of parameters while keeping the majority of the model’s parameters frozen, leading to a more efficient and resource-friendly adaptation process.
Why is Parameter-efficient Fine-tuning Important?
As machine learning models grow in size and complexity, the computational resources required for fine-tuning them become a significant concern. Parameter-efficient Fine-tuning addresses this challenge by reducing the number of parameters that need to be adjusted, which in turn lowers the computational cost and memory requirements. This efficiency makes it feasible to adapt large models to various tasks without requiring extensive hardware resources, thereby democratizing access to advanced machine learning capabilities.
How Does Parameter-efficient Fine-tuning Work?
PEFT operates on the principle that not all parameters of a model need to be adjusted to achieve good performance on a new task. Instead, by selectively fine-tuning only the most critical parameters, the model can be effectively adapted while preserving most of the pre-trained knowledge. Several techniques are employed to implement PEFT:
- Adapter Layers:
Adapter layers are small modules inserted into the existing layers of a pre-trained model. During fine-tuning, only these adapter layers are trained while the rest of the model remains unchanged. This approach allows for efficient learning with minimal changes to the model’s structure. - Low-Rank Adaptation (LoRA):
Low-Rank Adaptation involves adding low-rank matrices to the existing weights of the model. During fine-tuning, only these low-rank matrices are updated, which significantly reduces the number of parameters that need to be modified. - Prefix Tuning:
In prefix tuning, learnable vectors, known as prefixes, are prepended to the input sequences or intermediate layers of the model. Only these prefixes are fine-tuned, leaving the original model parameters untouched. This technique is particularly effective in natural language processing tasks. - BitFit:
BitFit is a method where only the bias terms of the model’s parameters are fine-tuned. Since bias terms constitute a small fraction of the total parameters, this approach is highly efficient in terms of both memory and computational costs.
Advantages of Parameter-efficient Fine-tuning
Parameter-efficient Fine-tuning offers several advantages, making it an attractive option for model adaptation:
- Reduced Computational Cost:
By fine-tuning only a small fraction of the model’s parameters, PEFT significantly lowers the computational cost associated with training. This reduction makes it possible to adapt large models on devices with limited computational resources. - Memory Efficiency:
PEFT reduces the memory footprint required for fine-tuning, as fewer parameters are stored and updated during the process. This efficiency is particularly beneficial when dealing with very large models that typically require substantial memory. - Faster Training:
Since PEFT involves fine-tuning a smaller number of parameters, the training process is generally faster compared to traditional methods. This speed is crucial when quick adaptation to new tasks is required. - Maintained Performance:
Despite the reduction in the number of fine-tuned parameters, PEFT often achieves performance comparable to full fine-tuning. This effectiveness demonstrates that a large portion of a model’s knowledge can be retained even when only a small subset of parameters is adjusted.
Applications of Parameter-efficient Fine-tuning
Parameter-efficient Fine-tuning is particularly useful in scenarios where computational resources are limited or when rapid model adaptation is necessary. Some of its key applications include:
- Natural Language Processing (NLP):
In NLP, PEFT is widely used to fine-tune large language models for specific tasks such as sentiment analysis, text classification, and machine translation. Techniques like prefix tuning and adapter layers are commonly employed in this domain. - Computer Vision:
PEFT is also applicable in computer vision, where large models are fine-tuned for tasks like image classification, object detection, and segmentation. The ability to adapt these models with minimal resources makes PEFT an ideal choice for deploying vision models in resource-constrained environments. - Transfer Learning:
Transfer learning, which involves adapting a pre-trained model to a new domain or task, can greatly benefit from PEFT. The efficiency of PEFT allows for the quick and effective transfer of knowledge from one task to another.
Conclusion:
Parameter-efficient Fine-tuning (PEFT) represents a significant advancement in the field of machine learning, offering a resource-efficient approach to model adaptation. By fine-tuning only a small subset of parameters, PEFT enables the effective and efficient adaptation of large models to new tasks, making advanced machine learning capabilities more accessible. As the demand for scalable and efficient machine learning solutions continues to grow, PEFT is poised to play a crucial role in the development and deployment of adaptable models across various domains.

Leave a comment