Introduction
In the age of artificial intelligence, Large Language Models (LLMs) have become integral to various applications, from chatbots to content generation. While many companies rely on public LLMs like GPT-4, there are significant benefits to building a private LLM tailored to your specific needs. This guide will walk you through the steps to create your private LLM, ensuring that your data and intellectual property remain secure.
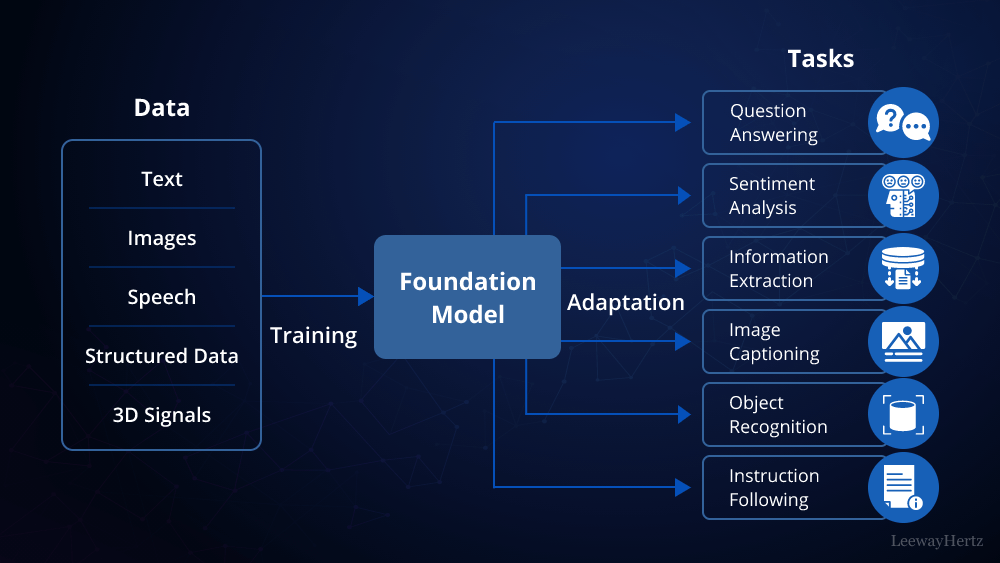
What is a Large Language Model?
A Large Language Model is a type of artificial intelligence that processes and generates human-like text based on a vast amount of data. LLMs are trained on diverse text data, allowing them to understand and generate text across various topics and styles.
Why Build a Private LLM?
- Data Privacy: Ensures sensitive information is not shared with third-party providers.
- Customization: Tailor the model to specific industry jargon, customer needs, and unique business requirements.
- Cost Efficiency: Potentially reduce long-term costs by avoiding subscription fees for public models.
- Performance: Optimize the model’s performance for your specific tasks and data.
Prerequisites
Before diving into building a private LLM, ensure you have the following:
- High-Quality Data: A large and diverse dataset relevant to your application.
- Computing Resources: Access to GPUs or TPUs for efficient training.
- Technical Expertise: Familiarity with machine learning frameworks and concepts.
Step-by-Step Guide on How to Build a Private LLM
Step 1: Define Your Objectives
Clarify the purpose of your LLM. Whether it’s for customer support, content creation, or data analysis, having a clear goal will guide your data collection and model training processes.
Step 2: Collect and Prepare Data
Data is the backbone of any LLM. Here’s how to prepare it:
- Data Collection: Gather a large corpus of text data relevant to your domain. This could include emails, customer service transcripts, product descriptions, and industry reports.
- Data Cleaning: Remove duplicates, correct errors, and ensure the data is in a consistent format.
- Data Preprocessing: Tokenize the text, remove stop words, and perform stemming or lemmatization.
Step 3: Choose the Right Framework
Select a machine learning framework suitable for training LLMs. Popular choices include:
- TensorFlow: Offers flexibility and a wide range of tools for deep learning.
- PyTorch: Known for its ease of use and dynamic computational graph.
- Hugging Face Transformers: Provides pre-trained models and tools specifically for natural language processing (NLP).
Step 4: Select or Design the Model Architecture
Decide whether to use a pre-existing architecture or design your own. For beginners, starting with a pre-existing architecture like GPT (Generative Pre-trained Transformer) is advisable. Hugging Face Transformers library offers various pre-trained models that can be fine-tuned to your specific needs.
Step 5: Train the Model
Training an LLM involves several steps:
- Initialize the Model: Load the pre-trained model or initialize a new model.
- Fine-Tuning: Use your domain-specific data to fine-tune the model. This process involves adjusting the model’s weights to better align with your data.
- Validation: Split your data into training and validation sets. Regularly evaluate the model’s performance on the validation set to avoid overfitting.
- Hyperparameter Tuning: Adjust parameters like learning rate, batch size, and number of epochs to optimize the model’s performance.
Step 6: Evaluate the Model
After training, evaluate the model using various metrics such as accuracy, perplexity, and F1 score. This step ensures that the model performs well on unseen data and meets your performance criteria.
Step 7: Deploy the Model
Once satisfied with the model’s performance, deploy it in your application. Consider the following:
- API Integration: Create an API endpoint for easy integration with your applications.
- Scalability: Ensure the deployment infrastructure can handle the expected load.
- Monitoring: Continuously monitor the model’s performance in production and retrain as necessary to maintain accuracy.
Step 8: Maintain and Update the Model
Building a private LLM is not a one-time task. Regular maintenance and updates are crucial:
- Retraining: Periodically retrain the model with new data to keep it relevant.
- Performance Monitoring: Continuously monitor the model’s performance and make necessary adjustments.
- Security: Regularly update security protocols to protect your data and model.
Conclusion
Building a private LLM involves careful planning, data preparation, and technical expertise. By following this guide, you can create a tailored LLM that meets your specific needs while ensuring data privacy and optimizing performance. Whether for customer service, content creation, or any other application, a private LLM can provide a significant competitive edge.
Remember, the key to success lies in continuous learning and adaptation. Stay updated with the latest advancements in AI and NLP to keep your private LLM at the forefront of technology.

Leave a comment