Introduction
In the realm of artificial intelligence and machine learning, the quest for efficiency is ever-present. One significant stride in this pursuit is Parameter-efficient Fine-tuning (PEFT). This approach promises to optimize the process of fine-tuning pre-trained models, making it not only faster but also more resource-efficient.
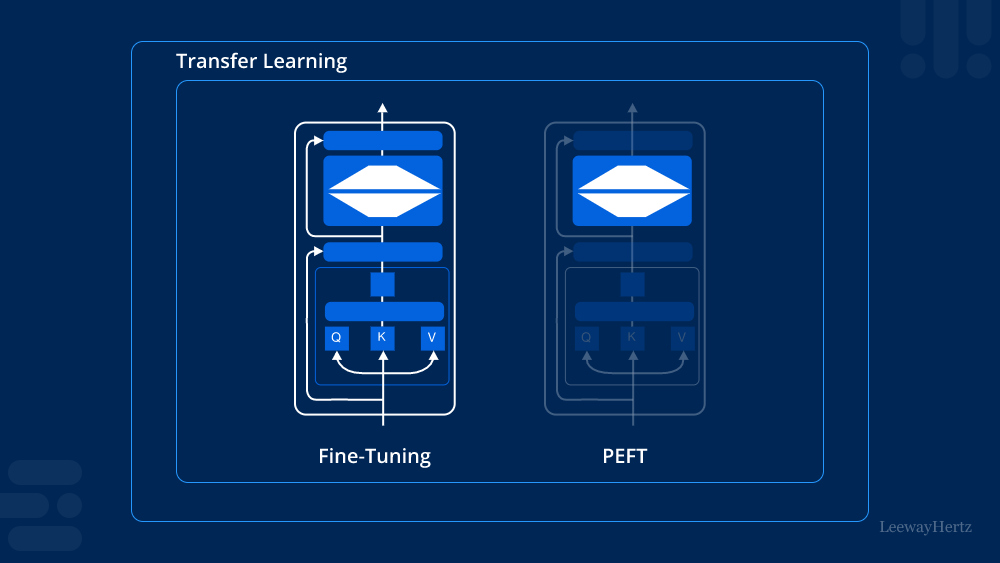
Understanding PEFT
Parameter-efficient Fine-tuning (PEFT) revolves around the idea of optimizing the fine-tuning process by selectively updating model parameters. Traditional fine-tuning typically involves updating all parameters across multiple layers of a pre-trained model, which can be computationally expensive and time-consuming, especially with large-scale models like BERT or GPT.
How PEFT Works
PEFT employs strategic strategies to fine-tune models efficiently:
- Layer-wise Fine-tuning: Instead of updating all layers uniformly, PEFT focuses on selectively updating specific layers that are more crucial for the target task. For instance, lower layers might capture more general features, while higher layers may specialize in task-specific details. By prioritizing updates in the relevant layers, PEFT reduces unnecessary computations.
- Gradient Scaling: Another technique involves scaling gradients during backpropagation. By adjusting the gradient magnitude based on layer importance or learning rate, PEFT ensures that updates are applied effectively without compromising model performance.
- Task-specific Parameter Adjustment: PEFT allows for task-specific adjustments in model parameters. This customization ensures that the fine-tuned model adapts optimally to the specific requirements of the target task, enhancing both performance and efficiency.
Benefits of PEFT
Implementing PEFT offers several key advantages:
- Faster Fine-tuning: By focusing updates on critical parameters, PEFT reduces the overall fine-tuning time significantly.
- Reduced Computational Cost: With fewer parameters being updated per iteration, PEFT decreases the computational resources required, making it feasible to fine-tune models on less powerful hardware.
- Improved Model Performance: Despite the reduced parameter updates, PEFT often leads to comparable or even improved performance on downstream tasks, thanks to its targeted optimization strategies.
- Scalability: PEFT is scalable across different types of pre-trained models and tasks, making it a versatile technique in various applications of machine learning.
Applications of PEFT
PEFT finds applications in a wide range of domains:
- Natural Language Processing (NLP): Enhancing sentiment analysis, text classification, and language translation tasks.
- Computer Vision: Improving object detection, image classification, and segmentation tasks.
- Recommendation Systems: Optimizing personalized recommendations based on user preferences and behavior patterns.
Challenges and Considerations
While PEFT offers significant advantages, there are challenges to consider:
- Fine-tuning Strategy Selection: Choosing the right strategy for PEFT depends on the specific model architecture and task requirements.
- Trade-off Between Efficiency and Performance: Balancing efficiency gains with potential impacts on model accuracy requires careful tuning and experimentation.
- Generalization Across Tasks: Ensuring that PEFT techniques generalize well across different tasks and datasets is crucial for widespread adoption.
Future Directions
The future of PEFT looks promising with ongoing research focusing on:
- Automated Fine-tuning Strategies: Developing automated approaches to dynamically adjust PEFT parameters based on real-time performance metrics.
- Integration with Transfer Learning: Enhancing the synergy between PEFT and transfer learning techniques to further improve model adaptation and efficiency.
- Application to New Domains: Extending PEFT methodologies to novel domains such as healthcare, finance, and robotics.
Conclusion
Parameter-efficient Fine-tuning (PEFT) represents a significant advancement in the field of machine learning, offering a streamlined approach to fine-tuning pre-trained models. By prioritizing critical parameters and optimizing update strategies, PEFT not only accelerates the fine-tuning process but also conserves computational resources without compromising performance. As research in PEFT continues to evolve, its potential to revolutionize various applications of AI and improve model efficiency remains promising.

Leave a comment