Introduction
In the realm of artificial intelligence and machine learning, pre-trained models have emerged as indispensable tools, offering a foundation of knowledge and capabilities that can be leveraged across various tasks. However, optimizing these models for specific applications requires careful consideration of resources and performance. This is where Parameter-Efficient Fine-Tuning (PEFT) steps in, offering a refined approach to fine-tuning pre-trained models for maximum efficiency and effectiveness.
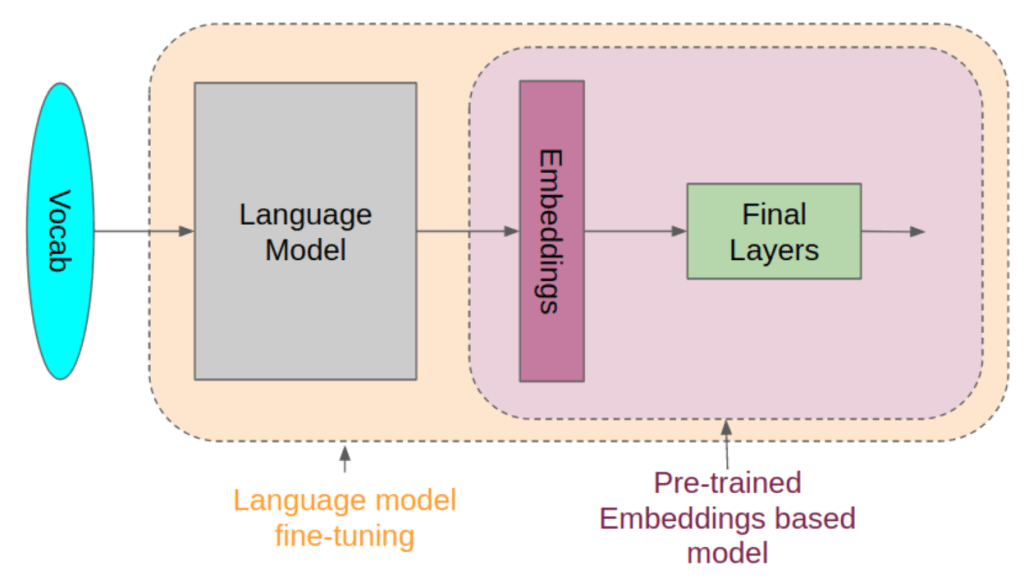
Understanding Pre-Trained Models
Pre-trained models serve as a backbone for many AI applications, providing a starting point with pre-learned features and patterns from vast datasets. These models are trained on extensive datasets, often requiring significant computational resources and time. Once trained, they can be fine-tuned on smaller, domain-specific datasets to adapt their knowledge to specific tasks, such as image classification, language understanding, or even generating text.
The Challenge of Fine-Tuning
While fine-tuning pre-trained models can significantly enhance their performance on specific tasks, it comes with its challenges. Traditional fine-tuning methods often involve updating a large number of parameters, leading to increased computational costs and potential overfitting, especially when dealing with limited data. This is where the concept of Parameter-Efficient Fine-Tuning (PEFT) comes into play.
Introducing Parameter-Efficient Fine-Tuning (PEFT)
PEFT is a technique aimed at optimizing the fine-tuning process by selectively updating only a subset of the parameters in a pre-trained model, rather than the entire set. By identifying and updating only the most relevant parameters for a given task, PEFT reduces computational overhead while preserving the generalization capabilities of the model.
Benefits of PEFT
- Computational Efficiency: By updating only a fraction of the parameters, PEFT significantly reduces the computational resources required for fine-tuning, making it feasible even with limited hardware resources.
- Reduced Overfitting: Focusing on updating a smaller subset of parameters helps mitigate the risk of overfitting, especially when dealing with small or noisy datasets.
- Faster Convergence: With fewer parameters to update, PEFT often leads to faster convergence during the fine-tuning process, allowing for quicker deployment of optimized models in real-world applications.
Implementing PEFT: Best Practices
- Task-Specific Parameter Identification: Identify the parameters most relevant to the target task by analyzing the architecture and objective of the pre-trained model. This may involve techniques such as feature importance analysis or task-specific parameter pruning.
- Gradual Fine-Tuning: Start with a conservative approach by updating only a small subset of parameters and gradually increasing the scope based on performance evaluation on validation data.
- Regularization Techniques: Incorporate regularization techniques such as weight decay or dropout to further prevent overfitting, especially when fine-tuning with limited data.
- Hyperparameter Tuning: Experiment with different learning rates, batch sizes, and optimization algorithms to find the optimal configuration for fine-tuning with PEFT.
- Evaluation and Iteration: Continuously evaluate the performance of the fine-tuned model on both validation and test datasets, and iterate the fine-tuning process as needed to achieve the desired balance of efficiency and accuracy.
Case Studies: PEFT in Action
- Image Classification: Fine-tuning a pre-trained convolutional neural network (CNN) for image classification tasks, focusing on updating only the final classification layers while keeping the lower-level feature extraction layers frozen.
- Natural Language Processing: Adapting a pre-trained language model for sentiment analysis or text generation tasks by selectively updating the attention mechanisms and output layers while preserving the learned language representations.
- Speech Recognition: Optimizing a pre-trained acoustic model for speech recognition applications by fine-tuning only the top layers responsible for mapping acoustic features to phonetic representations.
Future Directions and Challenges
While Parameter-Efficient Fine-Tuning shows promise in optimizing pre-trained models for efficiency and performance, there are still challenges and opportunities for further research. Future efforts may focus on developing more sophisticated techniques for identifying task-specific parameters, as well as exploring the integration of PEFT with other optimization strategies such as knowledge distillation and transfer learning.
Conclusion
Parameter-Efficient Fine-Tuning (PEFT) offers a pragmatic approach to optimizing pre-trained models for specific tasks, balancing computational efficiency with performance. By selectively updating only a subset of parameters, PEFT enables faster convergence, reduced overfitting, and more resource-efficient fine-tuning. As the demand for efficient AI solutions continues to grow, PEFT stands as a valuable tool in the AI practitioner’s toolkit, unlocking new possibilities for deploying sophisticated machine learning models in real-world applications.

Leave a comment